论文笔记 - Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
前言
现有的目标检测方法大多依赖于密集的anchor box,如faster rcnn,retinanet等,这些anchor box需要手工设定,且数量众多,同时会造成大量重复的预测,需要nms才能去除,因此使目标检测算法较为复杂。本文借鉴DERT中的set prediction思想,将RCNN算法中个手工设计的anchor生成的proposal转换为个可学习的proposal,减少了计算量,且由于proposal与gt为一一对应,因此无需使用NMS进行后处理,极大地简化了目标检测的流程。
论文:Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
代码:SparseR-CNN
背景

现有的检测算法,无论是基于grid的一阶段检测算法(如RetinaNet)或者是基于RPN的二阶段检测算法(如FasterRCNN),都依赖于密集的候选框,这样的设计会带来以下问题:
- 密集的候选框带来密集且重复的预测结果,因此不得不依赖于NMS进行后处理
- 多个候选框对应一个GT使得网络对分配规则较为敏感
- 最终的检测结果受手工设计的anchor的尺寸、长宽比以及数量的影响
因此,需要设计一个较为稀疏的检测器。在DETR中,目标检测问题转化成了set prediction问题,使得proposal变得稀疏(仅有100/300个),但是DETR中的每个query都需要和整个图片特征进行交互,因此作者任务DETR还不够稀疏。为此,作者提出了在box和feature层面都很稀疏的Sparse RCNN算法。
首先作者提出了可学习的proposal box(100个4-d坐标),但由于这些坐标仅包含位置信息,缺少如角度等其他信息,因此作为又提出了高维(如256维)的proposal feature,并通过Dynamic Instance Interactive Head来和ROI Feature进行交互,从而无需像DERT一样和整个图片特征进行交互。而在后续的实验中也可以证明proposal feature是网络的关键。
框架
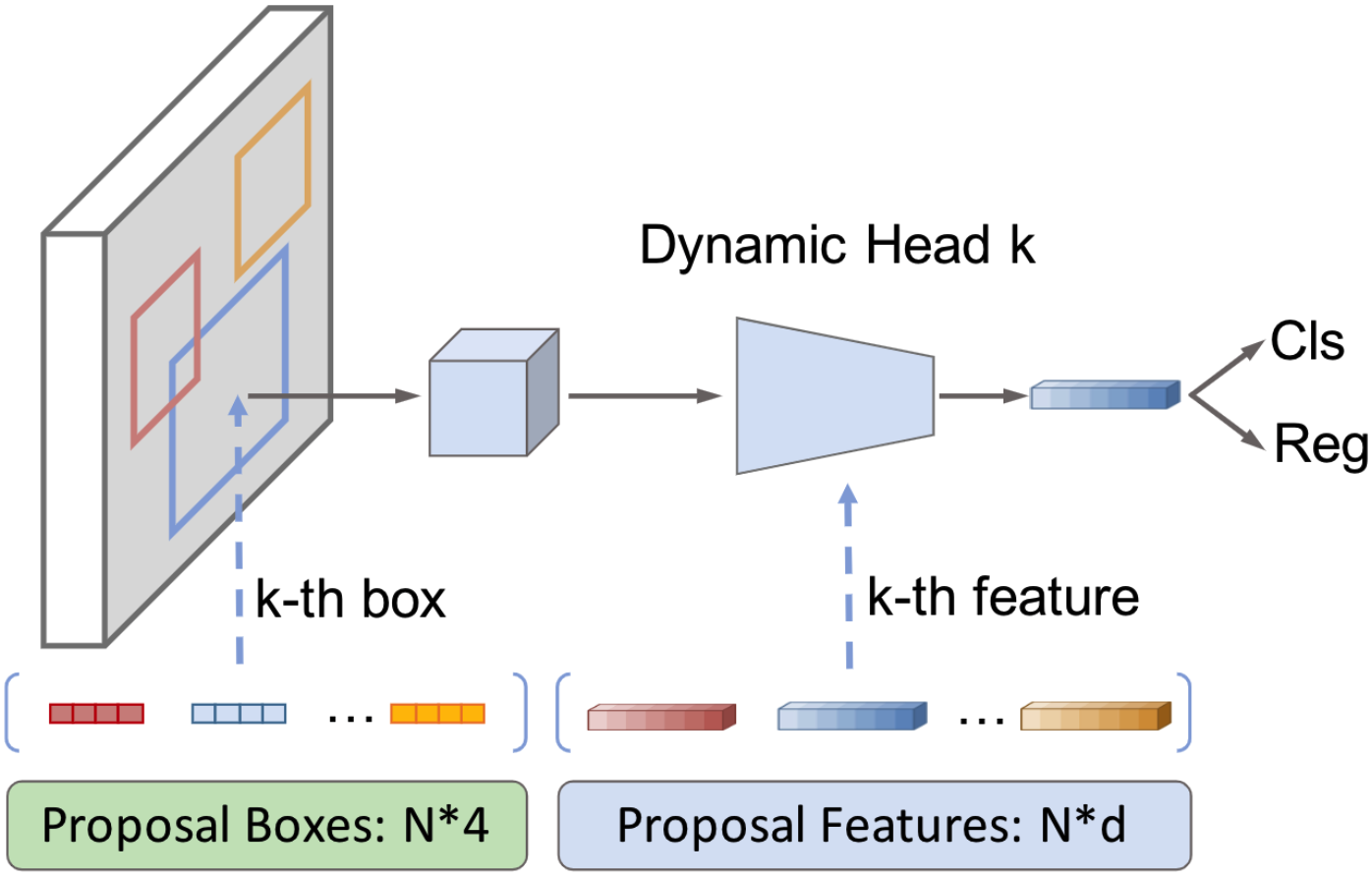
SparseRCNN的网络结构比较检测,由一个backbone,一个dynamic instance interactive head和2个特定任务的映射层组成,输出则包括三项:图片、proposal boxes, proposal features
Learnable proposal boxes
为维可学习的变量,用于代替RCNN中的RPN部分,取值范围0-1,代表归一化后的中心点和长宽
Proposal boxes可以视为从训练集中学到的物体可能出现的位置,鉴于RPN得到的proposal与具体图片相关且会被后续的网络进一步refine,因此作为认为proposal boxes就已经足够了(但这样更换数据集后泛化性是否减弱?存疑)。
Learnable proposal feature
由于proposal boxes仅提供了一个粗略定位,缺失较多信息,因此作者提出了proposal feature,相当于DETR中的object query,feature的数量和box数量一致
Dynamic instance interactive head
得到个proposal boxes之后,网络首先通过ROI提取对应的feature,然后每个RoI Feature回合对应的proposal feature进行交互(类似QKV和cross attention),过滤掉不相关的信息,并输出最后的obj feature

同时,作者还引入了迭代机制和self-attention机制
Iteration structure: head产生的bbox和obj feature,将会作为新的proposal bbox和proposal feature重新输出入网络进一步refine,在本算法中重复次数为6
Self-attention: 在进行动态交互前,obj features之间将会通过self-attention模块计算相互之间的关系
Set Prediction loss
loss和匹配cost与detr保持一致,为:
实验
与其他算法对比
作者实验了2个版本的SparseRCNN,第一个版本没有random crop且learned boxes数量为100,用于和常规RCNN对比。第二个版本使用了random crop且learned boxes数量为300,用于和DETR相比
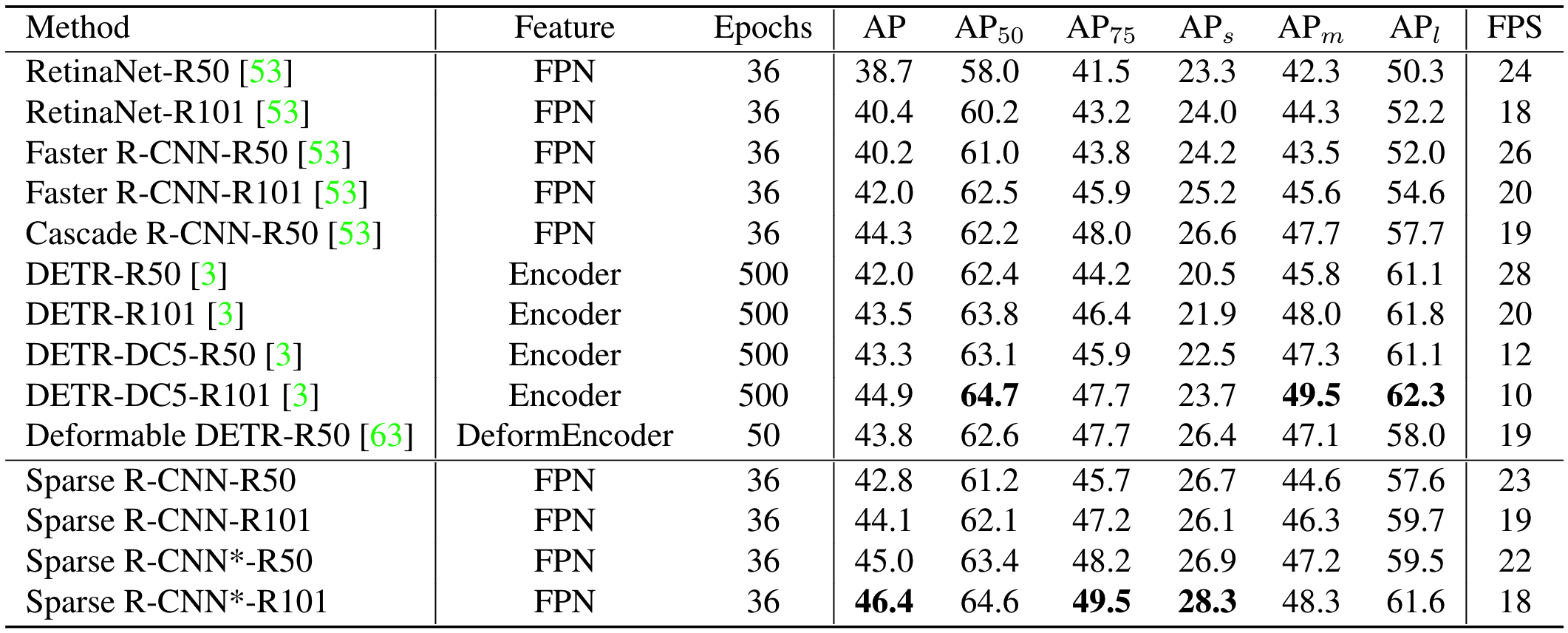
可以看出SparseRCNN指标比RCNN和Detr都要高,且在小目标上要优于DETR
模块分析
Learnable proposal box:仅将RPN替换为Learnable proposal box,性能急剧下降。

Iterative architecture:简单的堆叠效果不好。在实验中作者观察到box在每轮refine时基本都框柱同一个物体,因此本轮产生的obj feature作为可以一个很强的线索在下一轮中重复使用,因此作者将前一轮的obj feature和当前阶段的proposal feature进行concat,效果得到很大提升

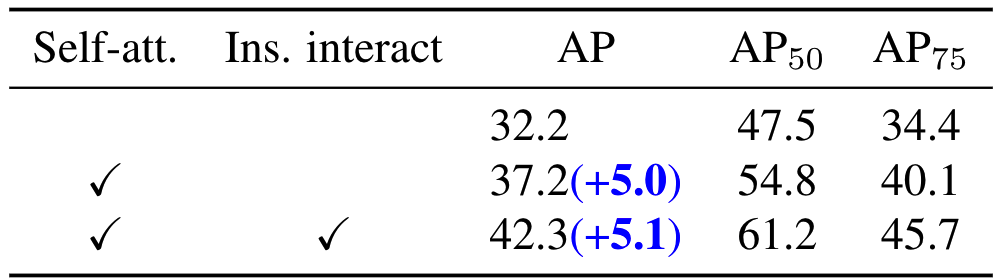
Dynamic head: 除了简单的concat,作者还测试了本文中的方式,即上一轮的obj feature先进行self attetion,然后再作为proposal feature进行instance interaction,各操作收益如下:
Initialization of proposal boxes: 由于以往的RCNN对anchor的设计较为重视,因此作者探索了proposal box的初始化是否有较大影响,结果显示SparseRCNN较为鲁棒

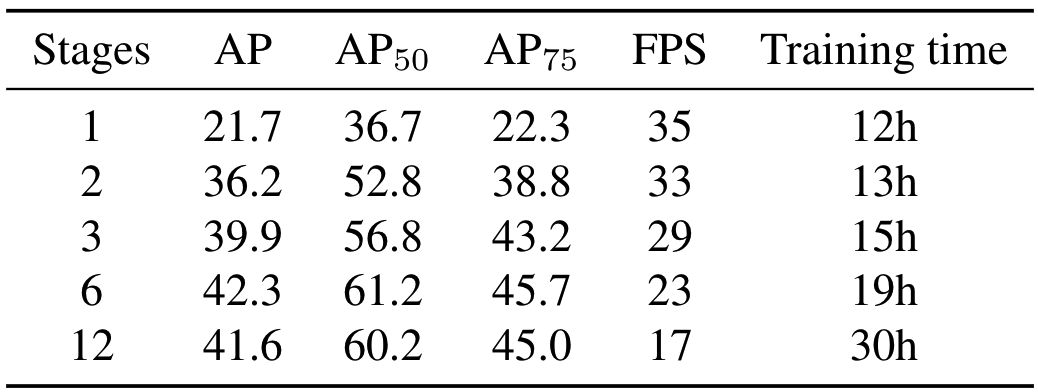
Number of proposals/stages in iterative architecture: 通过实验选择proposal boxes的数量为100/300,dynamic迭代次数为6

Dynamic head vs. Multi-head Attention: 二者理论上都可以对ROI feature进行过滤得到最终的obj feature,但实验证明本文的Dynamic head效果更好

Proposal feature vs. Object query: DETR中的object query相当于是一种学到的position encoding,用于指导图像feature和spatial positional encoding的交互,因此如果spatial positional encoding被去掉以后,DETR的性能会显著下降。而Proposal feature是一种feature filter,与位置无关,因此计算去掉spatial positional encoding后影响也不大

Proposal Boxes表现
可以看出Proposal Boxes在全图都有分布,这样可以保证较高的召回率。在迭代中,重复的框会逐渐消除且会更加精确。
