论文笔记 - OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
前言
在本篇论文中,作者提出了一种适用于任何任务、任何模态的框架,统一了多种多模态、单模态的任务,包括图像生成、图像分类、图像文本问答等任务。在预训练和微调阶段,OFA算法都适用了指示型学习的方法,在下游任务上不需要和任务相关layer。此外,OFA仅使用2000万公开的文本-图像对数进行训练,性能已经达到了SOTA水平,而且可以有效的迁移至未曾训练过的任务和模态上。
代码:OFA
背景
构建一个全能的模型是AI领域非常有吸引力的目标,它的关键在于能否通过少量的形式表达大量的模态、数据以及训练方法,并通过一个模型进行训练。Transformer的飞速发展带来了一定的可能性。一个全能的模型应该有以下特点:
- Task-Agnostic:不同类型的任务能够表达成统一的形式
- Modality-Agnost:不同模态的数据可以表达成统一的形式
- Task Comprehensiveness:支持足够多样的任务,以积累模型的泛化能力
与之对应的,现有的模型或多或少都有一些不足,包括:
- 多余的用于下游任务的可微调参数,如特定的层或者head
- 不同的任务优化方式及目标函数都不相同
- 模态表示和具体的下游任务没有解耦
在本文中,作者将不同类型的任务都抽象为seq-to-seq的形式,完成了统一,实现了Task-Agnostic。同时使用transfomer作为统一的框架,并将不同模态的数据转化到同一个字典中,实现了Modality-Agnost。作者在不同的多模态任务和但模态任务上都进行了pretrain,实现了Task Comprehensiveness,
框架
OFA框架如图所示,为一个同一的seq2seq结构,使用了统一的IO支持不同的任务

IO及结构
IO:对于不同模态的输入及输出,通过以下处理转化成统一的词典:
- 文本:使用BPE算法将文本拆分成sub-word,并进一步转化为embedding
- 图像:输入的图像经过ResNet转化为个patch的feature,输出图像经过sparse codin进行离散化,可将的图像转化为的token序列
- 图像中的物体:将物体的标签和位置转化为离散的token
结构:OFA使用transformer作为backbone,并采用encoder-decoder结构。对于文本和图像输入,OFA分别使用1D和2D的位置编码
任务及模态
OFA设计了一种统一的seq-to-seq的学习范式,将多模态和单模态的理解及生成任务进行了统一。
对于跨模态表征学习,作者设计了5个任务,分别是:
- Visual Grounding(VG):输入描述图像中物体的文本,输出物体的位置。即"Which region does the text describe?"
- Grounded Caption(GC):与VG相反,给定物体区域,输出描述文本,即"What does theregion describe? region:"
- Image-Text Matching(ITM):判断图像和描述文本是否匹配。即"Does the image describe ?“,回答"Yes"或"No”
- Image Caption(IC):输出描述图像的文本,即“What does the image describe?”
- Visual Question Answering(VQA):输入图像和问题,输出问题的正确答案
对于单模态的表征学习,作者设计了3个任务,分别是:
- Image Filling:掩盖图像中的部分区域,通过模型把缺失的图像补全。即“What is the image in themiddle part?”
- Object Detection:检测图像中的物体,输出物体标签和位置。即 “What are the objects in the image?”
- Text Filling:补全文本中被mask掉的字符。
预训练数据集:
作者使用的数据包括文本-图像对数据集、文本数据集、图像数据集,都为公开数据且进行去重
训练和推理
起初,作者在训练阶段使用Cross-Entropy Loss优化模型,即,其中为模型参数,推理阶段使用Beam Search策略进行解码,但这样做会有以下弊端:
- 在整个词典上进行优化效率低且没必要
- 在推理阶段会产生词典以外的token
因此,作者使用了基于前缀树的搜索策略,可以提升OFA的性能
模型扩展
作者提出了5种不同尺寸模型,最大的为或,其次为、、、来验证模型的扩展性
实验
跨模态任务实验
作者在不同的数据集上进行多个实验,如VQAv2(VQA任务)、 SNLI-VE(ITM任务)、MSCOCO(IC任务)、RefCOCO / RefCOCO+ / RefCOCOg(VG任务)、MSCOCO Image Caption(文本生成图像任务),实验结果如下所示:
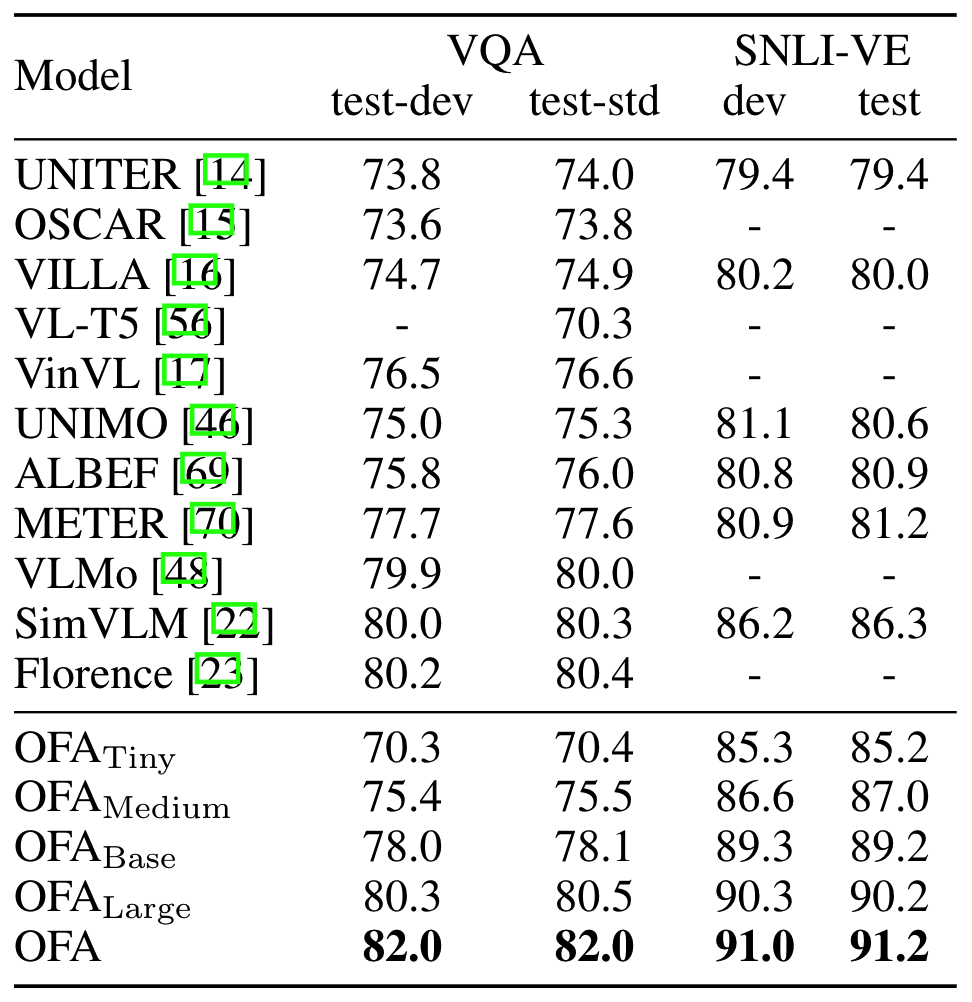
在VQA和SNLI-VE数据集上,即可超越SOTA模型,且效果更好
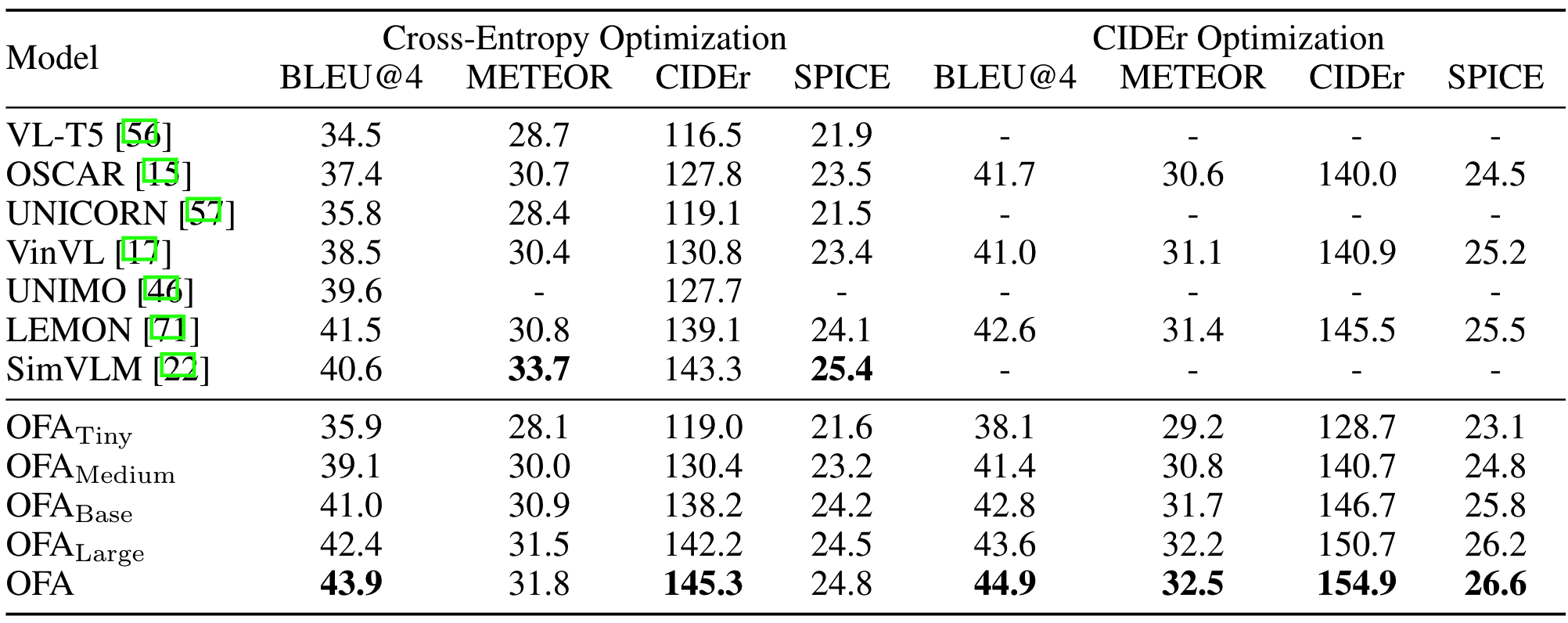
在MSCOCO数据集上,的单模型即可取得SOTA效果
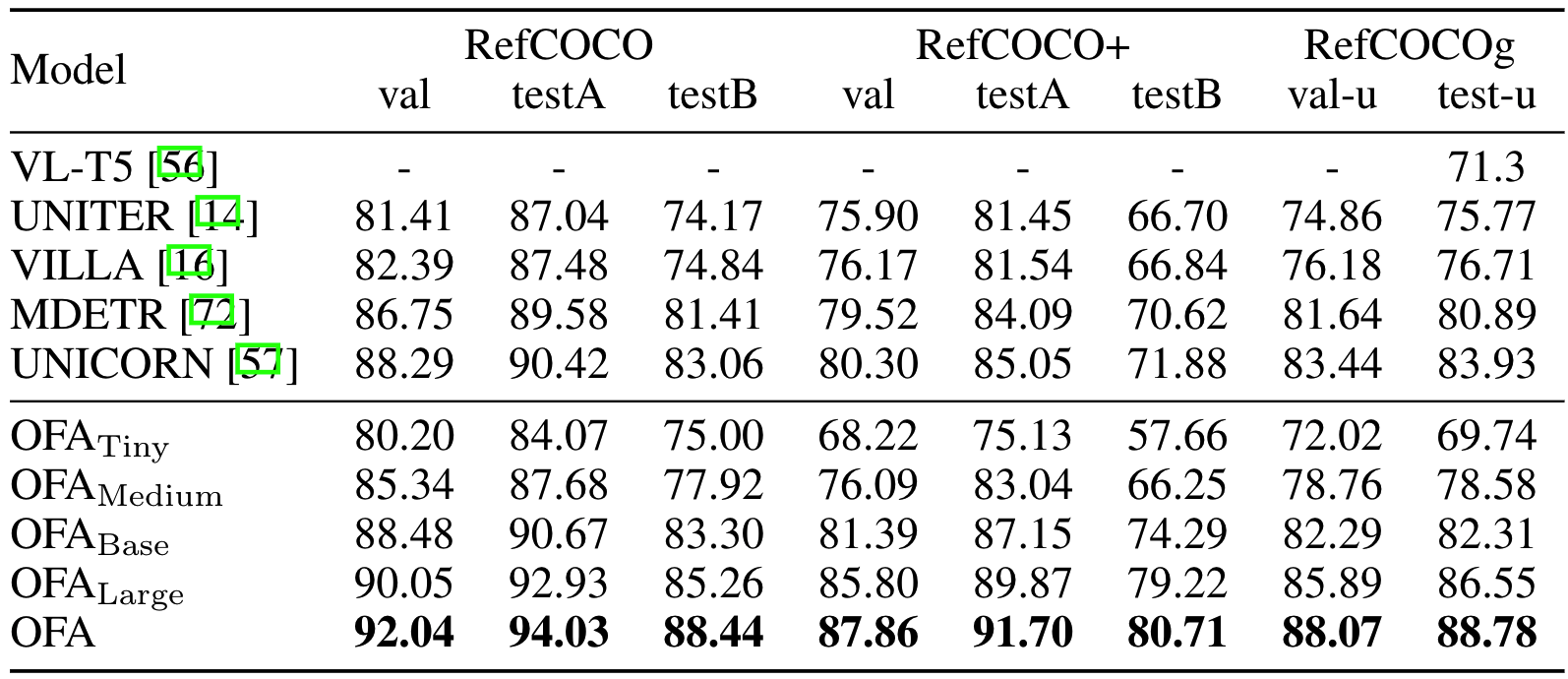
在RefCOCO系列数据集上,取得了SOTA结果且相较其他模型有较大提升
根据文本生成图像一直是一个较难的任务,作者在MSCOCO Image Caption数据集上,作者直接将进行微调来生成code,并通过一个code decoder来生成图像,通过对比,OFA以较小的sample size超过了DALLE、CogView和NÜWA,说明OFA可以更好的学到文本、图像和code间的关系

此外,作者还和DALLE、CogView对比了正常\反常识的query生成的图像,相比之下,正常query产生图像中,OFA的细节最为复杂,反常识的query产生的图像,只有OFA生成的图像符合描述

单模态实验
作者在不同的数据集上进行了单模态实验,如GLUE(自然语言理解)、 Gigaword abstractive summarization(自然语言生成)、ImageNet-1K(图像分类)
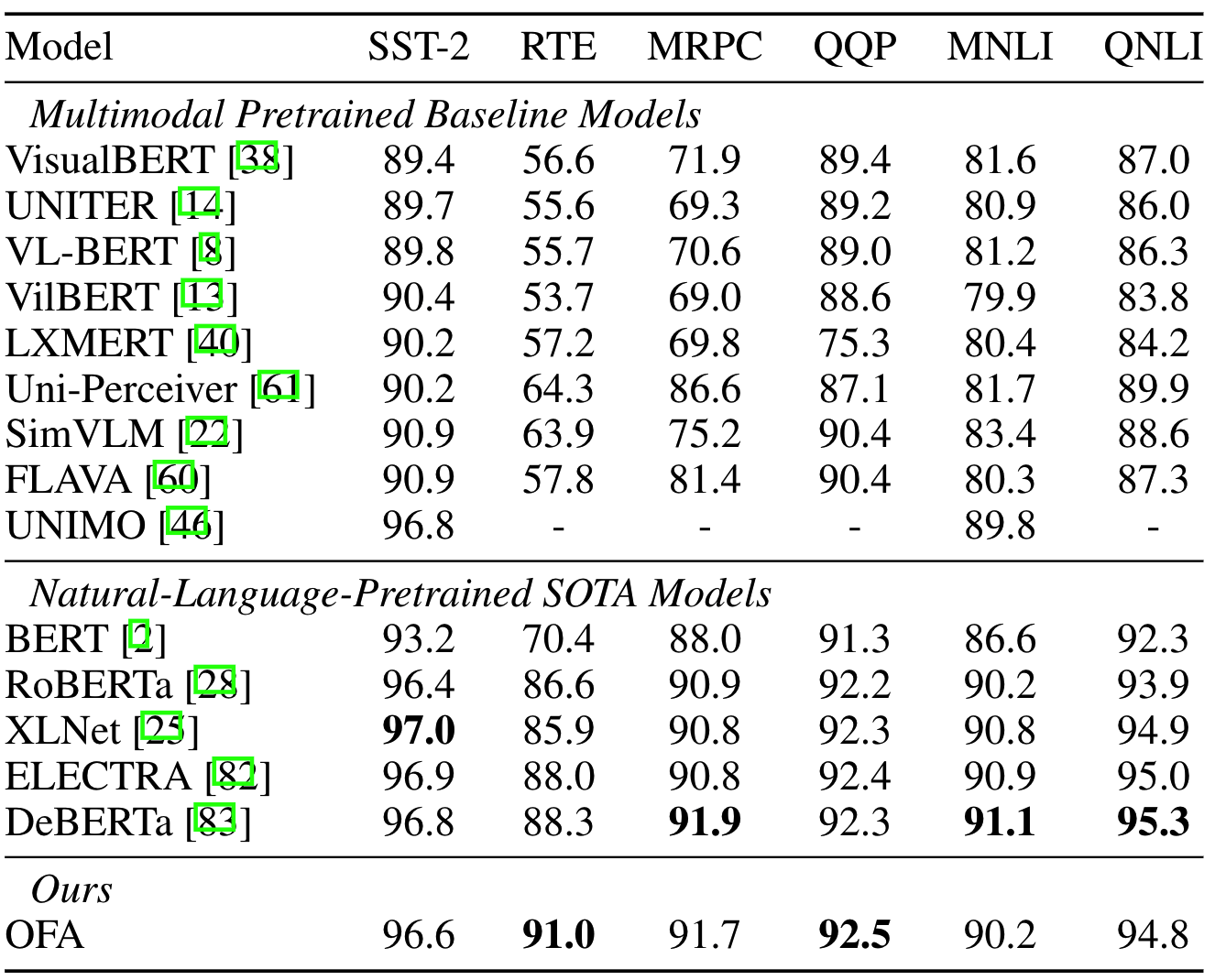
在GLUE的六个数据集上,OFA超过了所有多模态预训练的SOTA,甚至和单模态预训练的模型性能相当
在Gigaword数据集上,OFA成为了新的SOTA

在ImageNet-1K数据集上,OFA的性能和SOTA相当
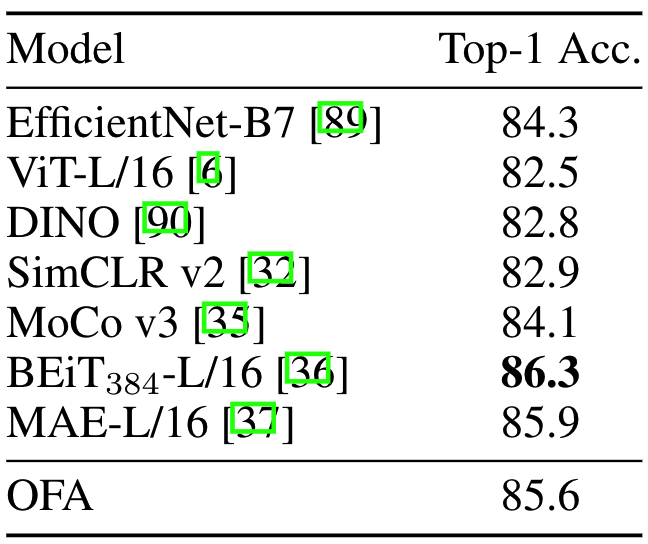
Zero-shot Learning & Task Transfer
在GLUE和SNLI-VE上测试zero-shot learning表现,OFA取得了较好的表现。但在此过程中,作者发现,模型的性能对问题的形式(例如“What is the image in themiddle part?”)较为敏感,微小的改变就会引起模型的性能,在未来的工作中可以进行挖掘

为了验证Task的迁移性,作者设计了一个全新的任务:Grounded Question Answering,即回答图像中物体相关的问题。OFA在这个全新的任务上也有较好的表现。

此外,对于训练中没有见过的合成图/动画,OFA也能取得较好结果

消融实验
通过消融实验,可以得到一些结论:
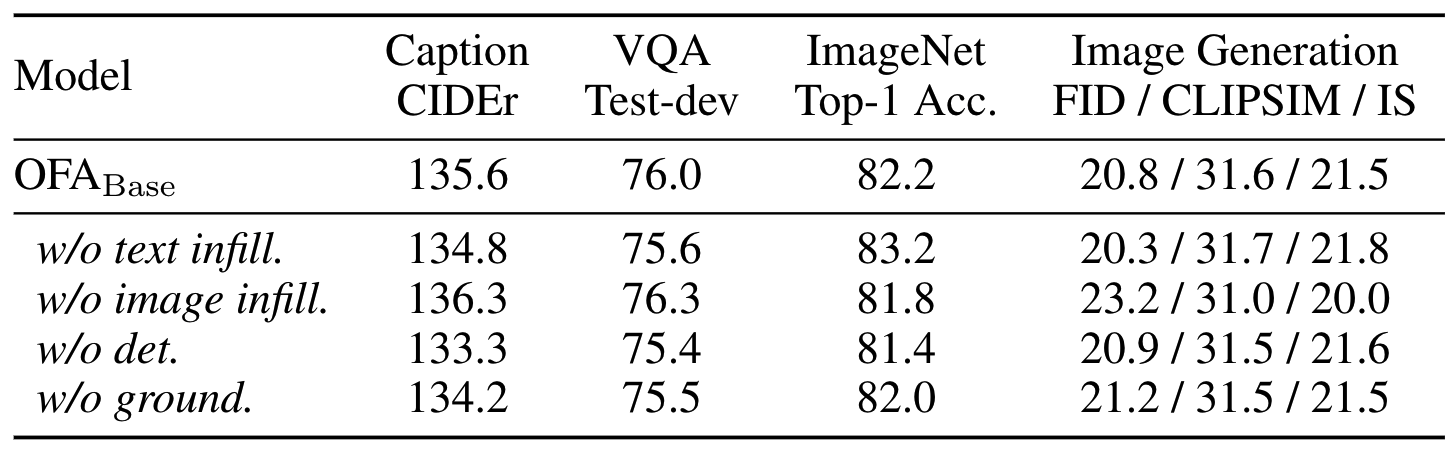
- Text Infilling任务可以提高Image Caption和VQA的性能,说明自然语言相关的预训练可以提高语言表征的学习,但是会损害图像特征的学习(ImageNet,Image Generation),可能是由于文本特征较为简单导致的
- Image infilling任务能提高图像表征的学习(ImageNet, Image Generation),但会降低文本表征(VQA,Image Caption)的学习
- Detection/Visual Grounding/Grounded Caption帮助模型掌握视觉和语言之间的细粒度对齐,提升了各任务的性能