Few Could Be Better Than All:Feature Sampling and Grouping for Scene Text Detection
前言
作者提出了一个简单的基于transformer的文本检测模型,该模型仅使用少量的feature进行文本检测,减少了背景干扰及计算量。在所有尺度的feature map上选取少量feature后,将其输入transformer中学习feature之间的关系,并将他们分成不同的组,每个组代表一个文本,并进一步计算文本位置。该模型不需要NMS等复杂的后处理,且性能达到了SOTA
论文: Few Could Be Better Than All:Feature Sampling and Grouping for Scene Text Detection
背景
传统的CNN检测算法依赖NMS等复杂的后处理,最近发展势头较好的基于Transformer的方法如DETR,对较小的目标检测性能较差且计算复杂高,如果使用分辨率较高的feature,会带来背景干扰并增加计算复杂度。作者认为,现有transformer方法计算所有像素之间的相关性是不必要的,因此,本文的算法首先选取和文本高度相关的特征,然后使用transformer来学习特征之间的关系,并将其进行分组,得益于transformer强大的注意力机制,每个分组能够正确关联到一个文本上,相比以往的算法,有如下优势:
- 减少冗余的背景信息,提高效率
- 使用transformer可以将特征正确分组,减少后处理
- 特征采样和分组是端到端进行的,可以对检测性能进行联合优化
框架

结构
backbone为R50+FPN,首先对每个层次的特征经过Coord Conv + deformable pooling后进一步下采样到更小的scales(),然后经过若干卷积层得到前景score map,然后从每个scale上选取top-个特征,进行gather后形成一个特征序列,维度为 ,然后进行特征分组
进行分组前,特征序列首先和位置编码进行concat,然后通过transforer encoder来学习特征点之间的关系,并隐式地将来自同一个文本的feature进行聚类,最后通过不同的head输出坐标及置信度信息
特征采样
多尺度特征提取:首先通过CoordConv在不同尺度的feature map上进行卷积:
为Res50+FPN中不同尺度()的特征,为归一化的坐标,经过卷积后,使用deformable ROI pooling对进行下采样,将特征进一步降低到更小的scale() ,得到。
最后,作者构建了一个由卷积层和Sigmoid函数组成的打分网络来获得score map,即,该网络每个尺度上的输出由二维高斯分布进行监督,来确保每个文本中心区域的分数最高
特征采样:得到score map后,在每个尺度上对score map进行排序,并对top-个得分最高的进行采样,得到
最终,大量的feature最终减少到与文本强相关的部分前景特征
特征聚类
为了保留采样特征的位置信息,首先将特征上和位置编码进行concat,然后通过transformer encoder的注意力机制来隐式的聚类特征
其中,为加入位置编码的特征,为通道数。计算atten时的复杂度由显著降低到。输出的特征经过2个head,分别预测坐标以及是否为文本的置信度
优化函数
目标函数由三部分组成,检测loss、分类loss、以及特征选择loss,与DETR类似,预测结果和GT通过匈牙利算法进行匹配
分类loss:使用CE loss
检测loss:使用GWD loss来更好的平衡不同尺度文本的检测loss,由于尺度变化较大,最小的文本对loss贡献几乎没有,因此本文使用loss调整为:
其中为预测框,为GT框,为求面积操作,为非线性函数。如果预测任意形状的文本,则预测贝塞尔函数的控制点(2个head分别预测上下曲线),否则预测bbox
特征选择loss:为score map和目标高斯分布间的smooth L1 loss
实验
数据集评测

多方向文本检测:在IC15和MSRA-TD500数据集上测试文本检测性能,与DETR类的算法相比,本文算法性能提升很大(83.7%->89.1%),与其他CNN类算法相比,在f-measure上也有1.7%的提升
弯曲文本检测:在Total-Text和CTW1500数据集上测试性能,较之前的SOTA提升约0.2%,由于预测的是贝塞尔曲线,在弯曲文本检测上,较现有的DETR类方法更加准确
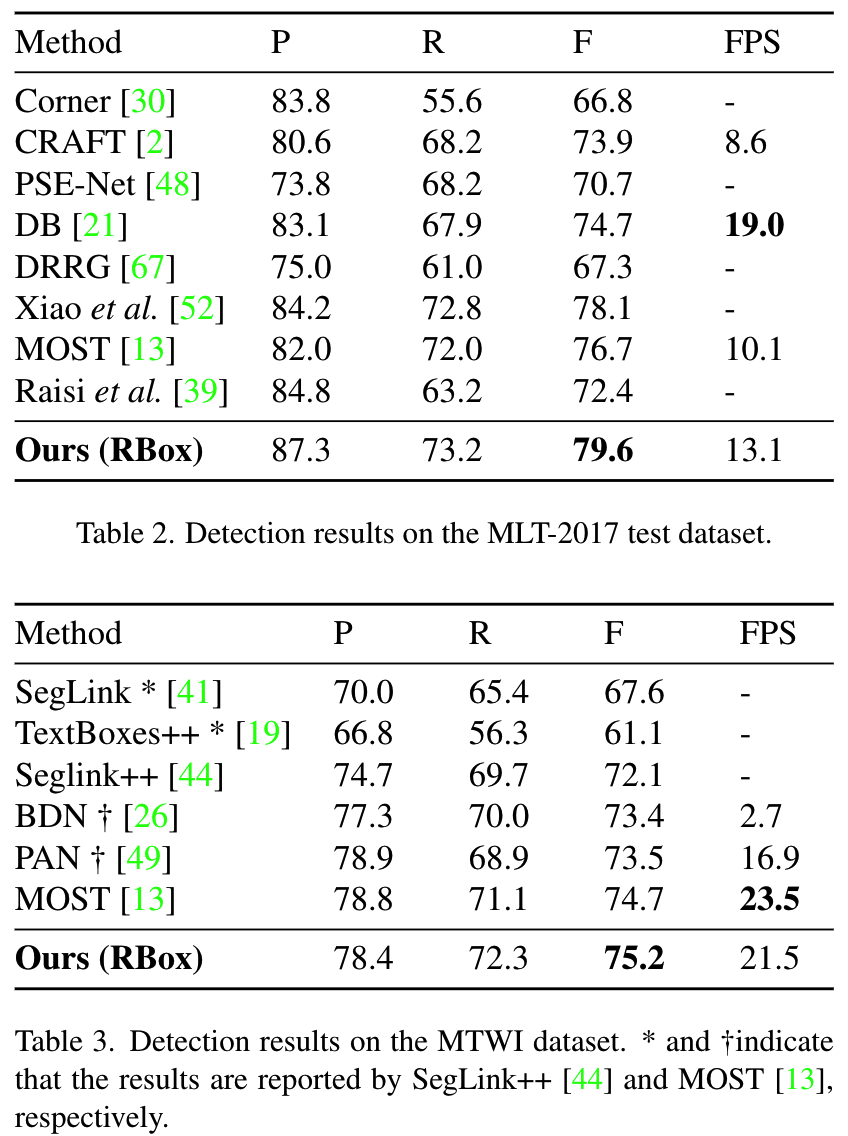
多语言文本检测:在MLT和MTWI数据集上测试文本检测在不同语言上的表现,相比SOTA算法,在P/R/F指标上都有所提升
特征采样实验
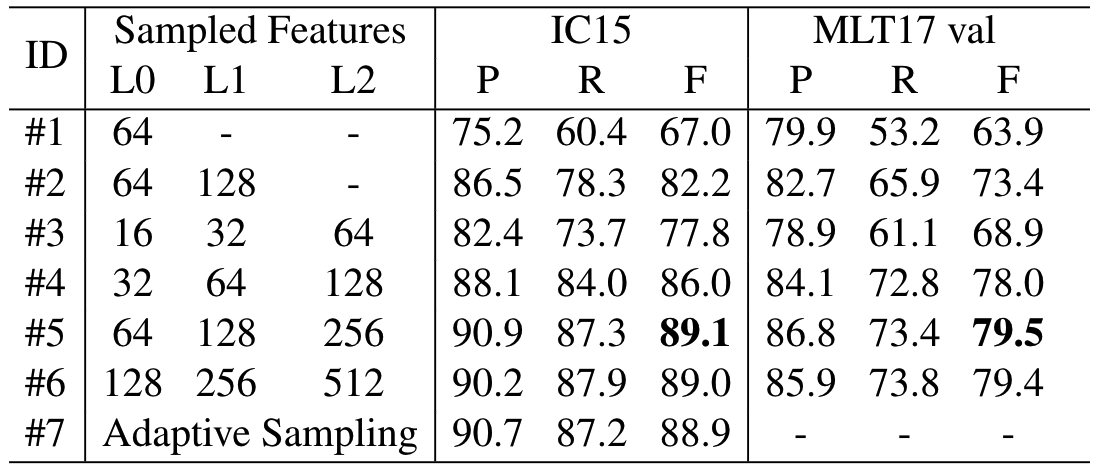
为了验证特征采样的影响,作者做了一组消融实验:
- 如#1、#2、#5所示,使用3个scale的feature,性能会大幅优于使用2个或1个scale时的性能
- 如#3、#4、#5、#5所示,增加采样点数量,性能首先会提升,然后就趋于饱和,这是由于较少的采样点数没有采集到足够的特征,但较多采样点会引入噪声
- 作者还测试了一种动态采样的方法,即将所有scale的feature按分数排序,取前25%作为采样点,但性能相比#5和#6没有较大提升,证明模型对超过#5中数量的采样点并不敏感
- 如果将所有的feature输入encoder,会出现显存溢出的问题,即计算复杂度太高
与Transformer类的检测算法对比
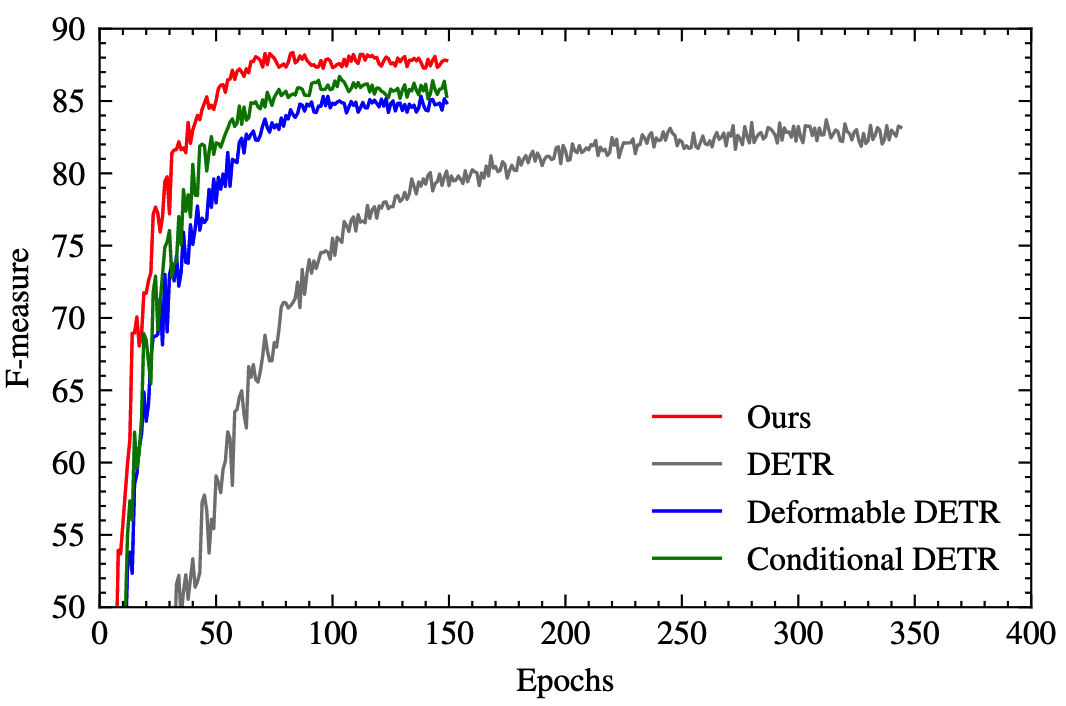
首先作者和几个DETR类的算法在SynthText数据集上进行收敛速度的对比,发现本文的算法收敛速度远快于DETR。与另外2个算法相比,收敛速度领先不多,但性能要更好。
在经过fine-tuning后,本文算法在IC15和MLT17上获得了最好的性能

在IC15上测试FLOPS,本文的算法FLOPS更低且推理速度更快
Transformer结构
将transformer中的层替换为Swin Transformer层后,在IC15和MLT17上的性能有所提升
旋转目标检测
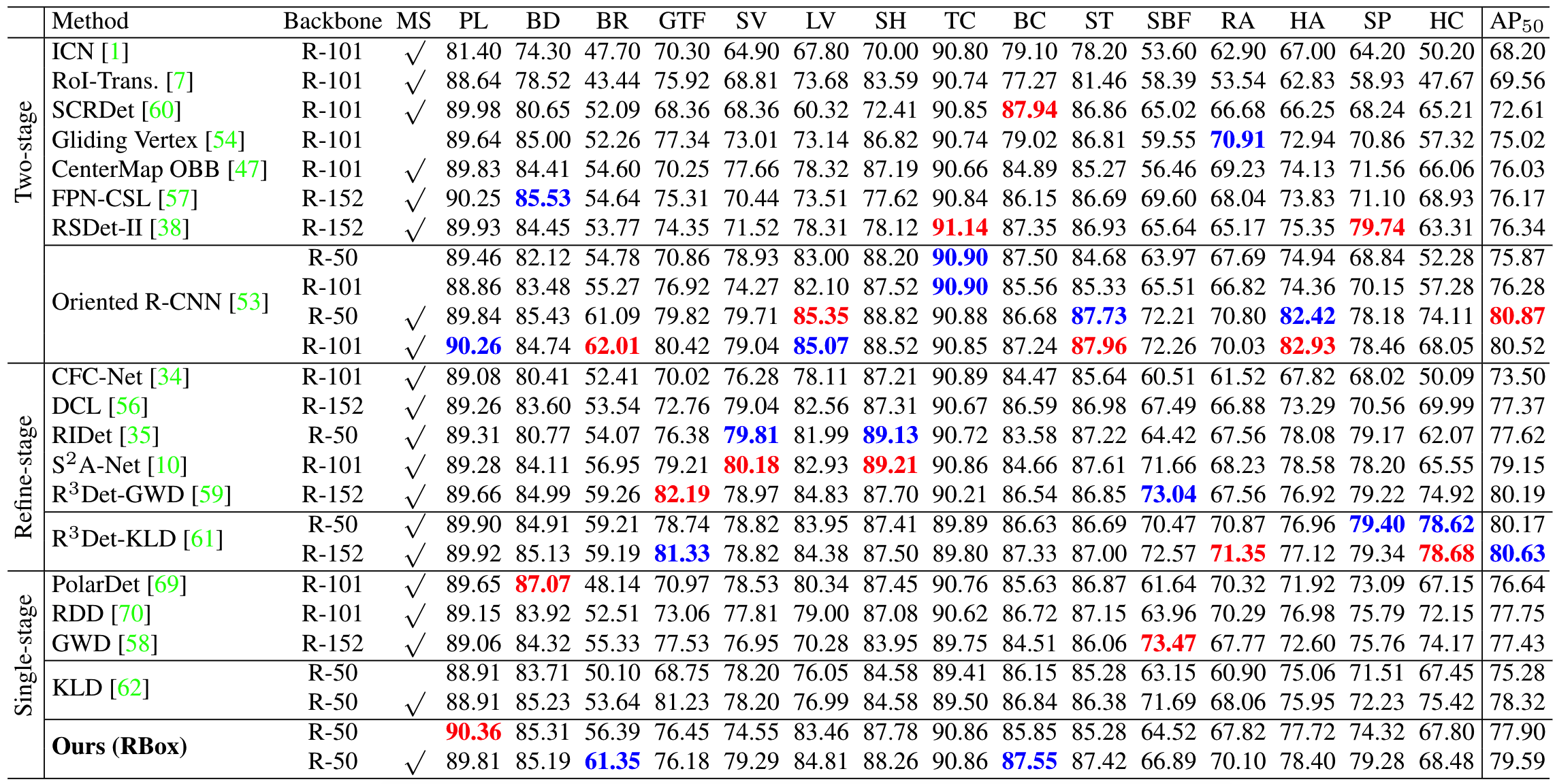
在DOTA数据集上测试本文算法的旋转目标检测的性能,在one-stage类算法中,本文的模型取得最好的性能,经过multi-scale测试后,本文模型取得了和SOTA相近的性能
限制

本文算法对存在重叠的文本检测效果不好,尽管encoder可以较好的学习feature间的attention,但重叠文本的feature关系较难学习,造成检测失败